Unless you’ve been living in a cave for the last year, you’ve probably heard of generative AI tools such as ChatGPT and Bard. Chances are, you’ve tested some out. Generative AI is already fusing with our daily processes, after all; Microsoft is embedding ChatGPT into its applications, just as Google is integrating Bard into G-suite tools.
So far, generative AI tools have gotten the most attention for the ways they help people in everyday life, such as using text-based outputs to write software code, college application essays, or a clinical treatment plan. Some use visual output to design websites or produce 3D models for video games, while a new Beatles song using an old clip of John Lennon’s voice uses audio-based output.
But generative AI is also improving existing technology – including computer vision. From generating fresh content to creating synthetic data, generative AI is bringing a new sophistication to computer vision technology.
Today we’re looking at four improvements to computer vision that generative AI is making, and how Chooch’s AI Vision Platform and new ImageChat model is unleashing these benefits.
From insight to innovation
If you’re not familiar with how generative AI works, it draws on several techniques. Most of us are familiar with large language models (LLM), a branch of machine learning. These models are trained on massive data sets, including text, images, and sounds. Using prediction algorithms, they respond to human prompts; our feedback and reinforcement learning helps them refine their output.
But generative AI does much more than answer questions. Here are four ways it works with computer vision to bring deeper insights and greater innovation to organizations.
#1. Improved quality and accuracy
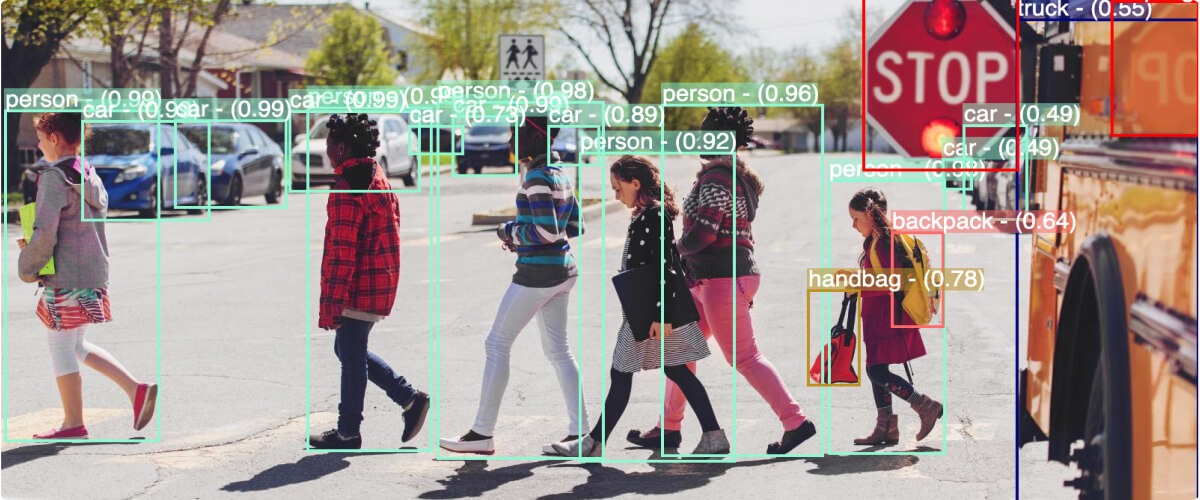
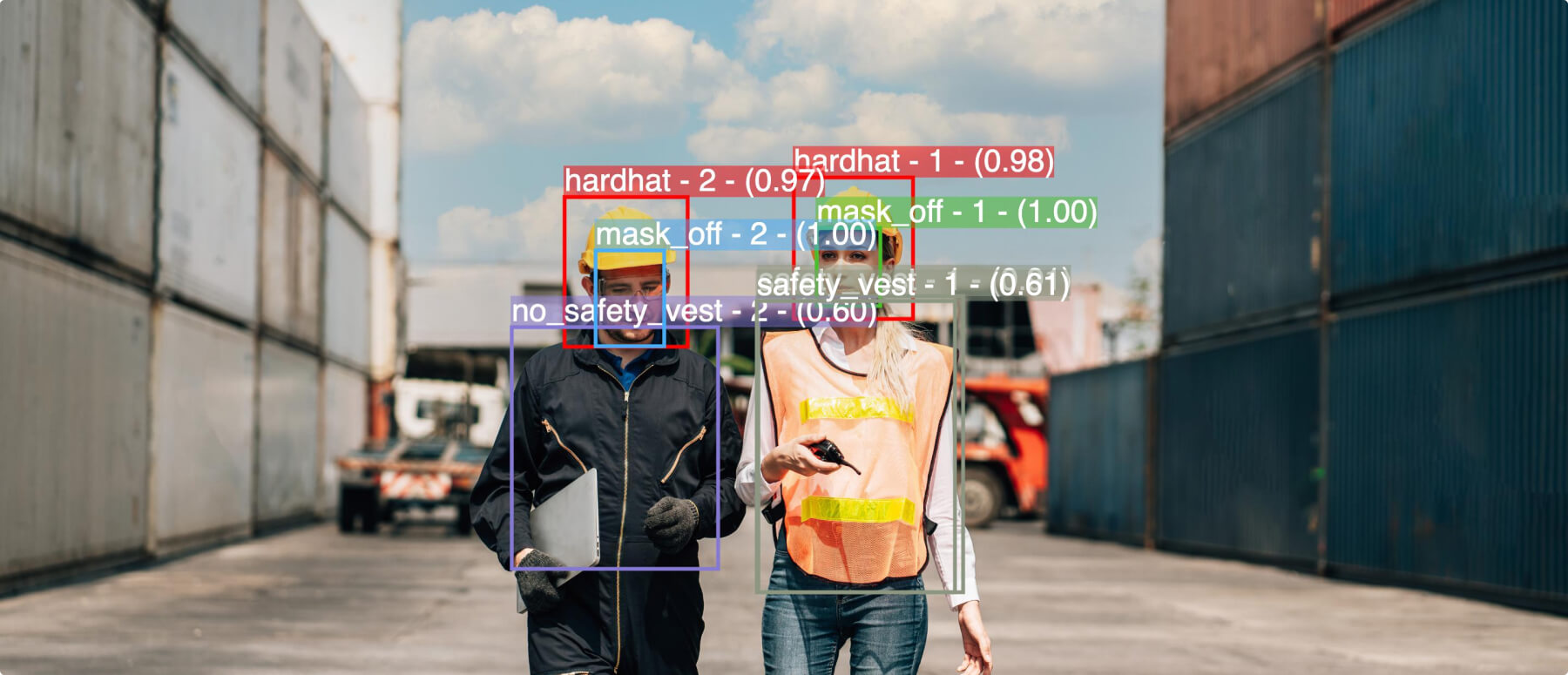
One of the primary computer vision use cases is to recognize and classify objects – from weapon detection to facial recognition to PPE checks. Generative AI enhances this ability by removing noise and artifacts from imagery and video, increasing image resolution, and canceling background noise. The result: sharper imagery, faster object identification, and fewer false positives.
This can be critical for a security team using computer vision to detect weapons at a school or a factory monitoring PPE compliance to prevent shop floor accidents. It can also help clinicians use highly detailed medical imaging scans in ultrasound, x-ray, computed tomography (CT), or magnetic resonance imaging (MRI) to diagnose conditions, understand where to place a biopsy needle, or form a treatment plan.
#2. The creation of realistic images
Because generative AI can create extremely realistic new images and videos, it can assist computer vision by generating original 3D models of objects, machine components, buildings, medications, people, landscapes, and more. Users don’t have to search for an actual image or footage that already exists; they can simply develop their own and extract more useful insights.
For an engineering company, this could take the form of designing innovative new products via simulation; federal organizations could develop smarter prevention and mitigation strategies for wildfires and other natural disasters by analyzing realistic footage and photos of simulated events to understand how they would unfold.
#3. Synthetic data
Data is the lifeblood of computer vision, but data annotation has been a barrier to AI adoption. Generative AI overcomes this barrier by creating synthetic, automatically labelled, new data elements that help train computer vision models how to see, learn, and predict.
Although organizations have been reluctant to share sensitive data with third parties because of the security risk, privacy is no longer a concern as synthetic data can’t be linked to a real person. This also addresses the ethics issue of bias in models; while teams have worried about bias filtering into models through the data they’re trained on, synthetic data can eliminate any possibility of bias.
#4. More comprehensive data resources
Computer vision models are trained on vast quantities of data – but some generative AI models tap into even bigger data stores, including data that’s never been leveraged before. Combining computer vision AI and large language models for image-to-text provides the ability to gain more detailed insights into visuals.
Analysts can craft targeted prompts to obtain specific information based on what’s most important to their business. For example, they can ask questions like “what objects are present in this image?” or “where is the person located in the video?” By fine-tuning text prompts, they can narrow down their text queries to extract precise information which they may not have been able to do before.
More actionable, higher quality data enhances the accuracy of computer vision tools and accelerates the benefits that they bring to organizations.
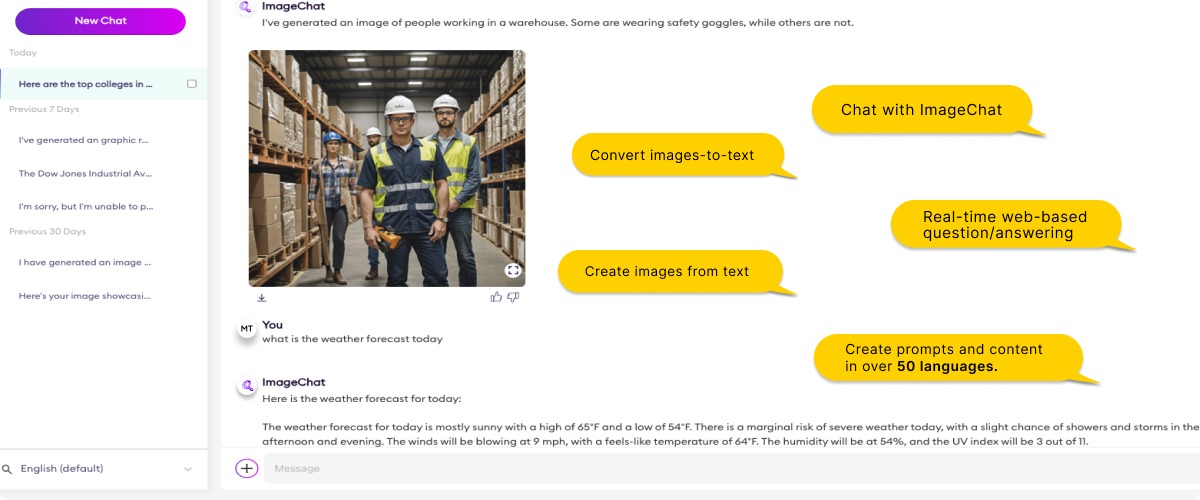
Chooch is taking generative AI capabilities to the next level with ImageChatTM
Chooch is one of the few companies globally that currently offers generative AI technology for image-to-text. Chooch recently released, ImageChat, a generative AI foundational model that combines computer vision and large language models (LLMs) for creating text prompts to gain more detailed insights into video stream visuals.
ImageChat is pre-trained on vast amounts of visual and language data combined with object detectors to generate localized, highly accurate detection of even the most subtle nuances in images with staggering accuracy. It can recognize over 40 million visual elements – offering a revolutionary way to build computer vision models using text prompts with image recognition.
Computer Vision AI + Large Language Models = Chooch AI Vision
With image-to-text technology, Chooch’s AI Vision platform goes beyond traditional computer vision algorithms to incorporate generative AI that can automate the process of extracting information from visual content to significantly reduce analyst review times and manual efforts, while creating actionable, higher quality data in real-time.
Equipped with these dynamic and context-aware data insights, Chooch’s AI Vision platform can solve a broader range of problems and challenges. Simply put, computer vision AI can now go to an unprecedented level of accuracy and intelligence.
Computer vision has always been about the precise analysis of visual information. Generative AI helps translate imagery into more actionable, higher quality data in unprecedented new ways. How will you take advantage of this new era in computer vision? Schedule a demo to explore the full capabilities of Chooch’s AI Vision platform and ImageChat.
To begin developing your own AI models, sign up for a free Studio Account. For access to the ImageChat API, you’ll need an Enterprise Account—please contact our customer support team for further assistance.